AI Coding Assistants - Looking Back and Forward
⋅ tags: ai hci programming
est. reading time: 21 mins, 4317 words
In the last two years, our AI community has learned a lot about large language models (LLMs) and how we could use them for human needs, including the need for building better, faster, and more reliable software. For much of this period, I was the product manager in a team that built AI coding assistants and closely followed the flow of ideas and discourse in this field. I want to compile and share in this blog post insights I compiled while working in the AI field, regarding building the next-generation AI coding assistant across four main themes:
(click to jump to section)
This post is an updated adaptation of my short position paper Envisioning the Next-Generation AI Coding Assistant: Insights and Proposals, which won the Best Paper Award at the JetBrains IDE Workshop in ICSE ‘24.
***
Context
Fall 2022, in a pre-ChatGPT world, there were a small but growing number of AI coding tools on the market.
They leveraged OpenAI Codex or proprietary in-house completion models to write code (GitHub Copilot, TabNine), comments (Mintlify), unit tests (DiffBlue), etc. This early generation of AI coding assistants provided simple interfaces to generate predictions based on the existing content. Users had controls over:
- input – code and text snippets to generate next-token or fill-in-the-middle predictions;
- processing parameters – user settings such as generation length, temperature, pre- and post-processing procedures;
- acceptance – decision to insert code and text suggestions into the working environment.
The early adopters of these tools were a small base. Companies were aware of AI-assisted assistants but unwilling to roll them out at work over concerns of intellectual property violations, data privacy and security hazards, as well as quality inconsistency. At this time, AI researchers and practitioners mostly focused on improving the foundational models and identifying specific use cases where AI could best assist developers.
With the meteoric rise of ChatGPT, everything changed.
The field largely moved away from completion models and diverted attention towards instruction-tuned, conversational LLMs, which led to a rapid proliferation and advancement of such models from both closed- and open-source organizations.
This shift in the foundational technology spilled over to application design and user experience, where the default mode of human-AI interactions became multi-turn conversations. The conversation window became the main user interface, regardless of the diverse user aims in AI-assisted applications, causing an era of yet-another-chatbot fatigue.
However, in recent months, there has been a strong resurgence of straightforward auto-completion (particularly in code suggestions) and steady emergence of task-specific AI-assisted workflows, as well as more ambient modes of human-AI interaction.
Predictions of an AI-assisted productivity boom in key industries, with emphasis on software development, set off the race to build and rollout the next-generation AI coding assistants. Large sums of fundings expanded the field, attracting new researchers and practitioners to the field of AI, testing new ideas and apparatuses to make AI more helpful for coding tasks, ushering in fast-paced knowledge advancements and product innovations.
A refreshed interest (and fear of missing out) drove more mainstream adoption of AI coding assistants in tech companies, escalating the needs for administrative capabilities from usage policies, monitoring, auditing, and impact measuring.
Yet in a boom of new ideas and possibilities, I want to take a pause to curate and reflect on core concepts and existing challenges to make AI helpful and reliable for developers. Our community of programmers are simultaneously the builders, supporters, critics, benefactors and beneficiaries of this technology. By focusing our efforts on the right challenges, we can usher in a new era of AI-assisted software engineering, improving the coding process and developer experience.
1. Human-centered AI
The emergent capabilities of foundational LLMs to generate coherent and relevant text to various requests have inspired many ideas for applications, serving a wide variety of human needs:
- informational – generative search, Q&A, knowledge recall
- educational – personalized tutoring, adaptive lesson plans
- recreational – creative content generation
- emotional – romance bots
- professional – call center, communication assistance, automated reporting, etc.
LLM potential ranges extensively because a lot of human activities are text-based. However, foundational LLMs need to be wrapped under thoughtful application designs to materialize their potential.
Building applications with LLMs poses unique challenges. One is aligning LLMs' generative variability with human values and needs. Two is incorporating AI tools effectively into workflows of solving tasks that require complex cognitive (and intuitive!) abilities beyond textual processing.
Complete automation is barely a feasible option. Instead, we should focus on working towards a system that combines human control and AI assistance, which is precisely the goal of human-center AI design.
Foundational resources:
- Google People + AI Research
- IBM Design for AI
- Human Centered AI Book
- JetBrains Literature Review of In-IDE Human-AI Experience
Human-centered AI design investigates the unique characteristics of generative AI from the perspective of user experience design and consequently provides basic guidelines to improve human-AI interactions. Some main areas of recommendations include:
- Design for mental models & user aims
- Design for multiple outputs & variability
- Design for human controls & feedback
- Design for imperfections, errors & fallbacks
- Design for explainability & trust
- Design against harm
(adapted list from Google’s Human-AI Interaction guidebook and IBM’s paper Toward General Design Principles for Generative AI)
Covering all of these areas would be impossible for the scope of a blog post, that’s why I will limit my deep-dive here to only the first area of recommendations, Design for mental models & user aims.
By definition, a mental model is a person’s framework to interpret reality. In the context of AI coding assistants, designing for mental models means accommodating the different preconceived notions of AI that the users might have and guiding their understandings and expectations to match with the product’s actual capabilities.
A common frustration shared by early adopters of AI coding chatbots results from mismatched expectations set up by the product presentation & marketing with actual user experience – failure to design for mental models. The low-fidelity user interface of a chat window of turn-taking conversations allowed and encouraged the users to put in free-form text for any requests related to coding. A common product tagline trope was, “you can ask the product anything, and AI will do it for you” – a long-shot exaggeration.
Users soon found out that in fact, they couldn’t just ask AI anything to get the assistance that they wanted. And no, this problem cannot be solved entirely by “prompt engineering”. Some requests required so much context that it would take too much time to collect and write up all that information in a prompt. On top of that, the stochastic nature of LLMs often conflicted with the precision required in coding, with the slightest deviation in the generation step leading to irrelevant, wrong, or unhelpful responses.
The prompting interface also became a breeding ground for misuse, as bad-faith users try to break safeguards through prompt injections, requesting the underlying LLM to give responses outside of the intended usage. To address this problem, AI coding assistants might double down on implementing stricter filters, yet they run into the problem of falsely rejecting legitimate requests, costing users time and effort to maneuver around the restriction policies.
This is not to say that we should abandon chat windows. It is a simple and powerful interface for free-form requests. Chat windows have also improved a lot since the added capabilities for automatic prompt augmentation and tool integration, as well as the advancements in foundational LLMs where new models are better trained to align with human values and expectations. People get the responses they want from chat windows more easily now than before. However, we should avoid overreliance on chat as the default interface for coding assistance.
When tackling complex tasks, we humans don’t rely solely on free text exchanges, but more importantly, protocols and processes. Especially in our field of computer science, predicated on algorithms, we understand the utmost importance of a rigorous sequence of instructions, a thoughtful procedure. While working with my team on building our AI coding assistant, I dedicated most of our limited budget for research & development efforts to develop features that we called “predefined workflows” where users do not prompt, but engage with LLMs through a curated process with more traditional modes of interactions – browse, filter, select, commit, etc.
An example is the code refactor workflow based on linter findings. By typing the slash comment /refactor from the chat window, users are taken to a new window that guides them through a multi-step procedure:
- review the list of findings – browse the issues detected by rule-based linters, with extra labels generated by AI that suggest edit impact predictions (edit impacting a single line, or a function, a file, or cross-files), preview the isolated edits of individual issues without combining fixes from other issues
- tune settings and parameters – choose what findings to tackle, whether to apply templated, rule-based edits if applicable (to save AI incurrence cost),
- monitor – get updates on the progress and partial results throughout the server-side procedure
- browse potential solutions – stage and review AI-generated changes alongside explanations
- decide – whether or not to commit the suggestions into their source code, edits are saved in an edit history that can be reversible when conditions allow
This code refactor workflow utilizes existing mental models of linter remediation & change list review, processes that developers are already familiar with. The prompt engineering steps are abstracted and relegated to the tool builders’ responsibility.
While coding, developers obviously have more needs outside of linter remediation. By applying the principles of mental models and user aims, we can further break down different types of problems during software development, investigate how programmers are already solving those problems, and brainstorm how AI might enhance their workflows. Here’s my reference model of human-AI interactions while coding:
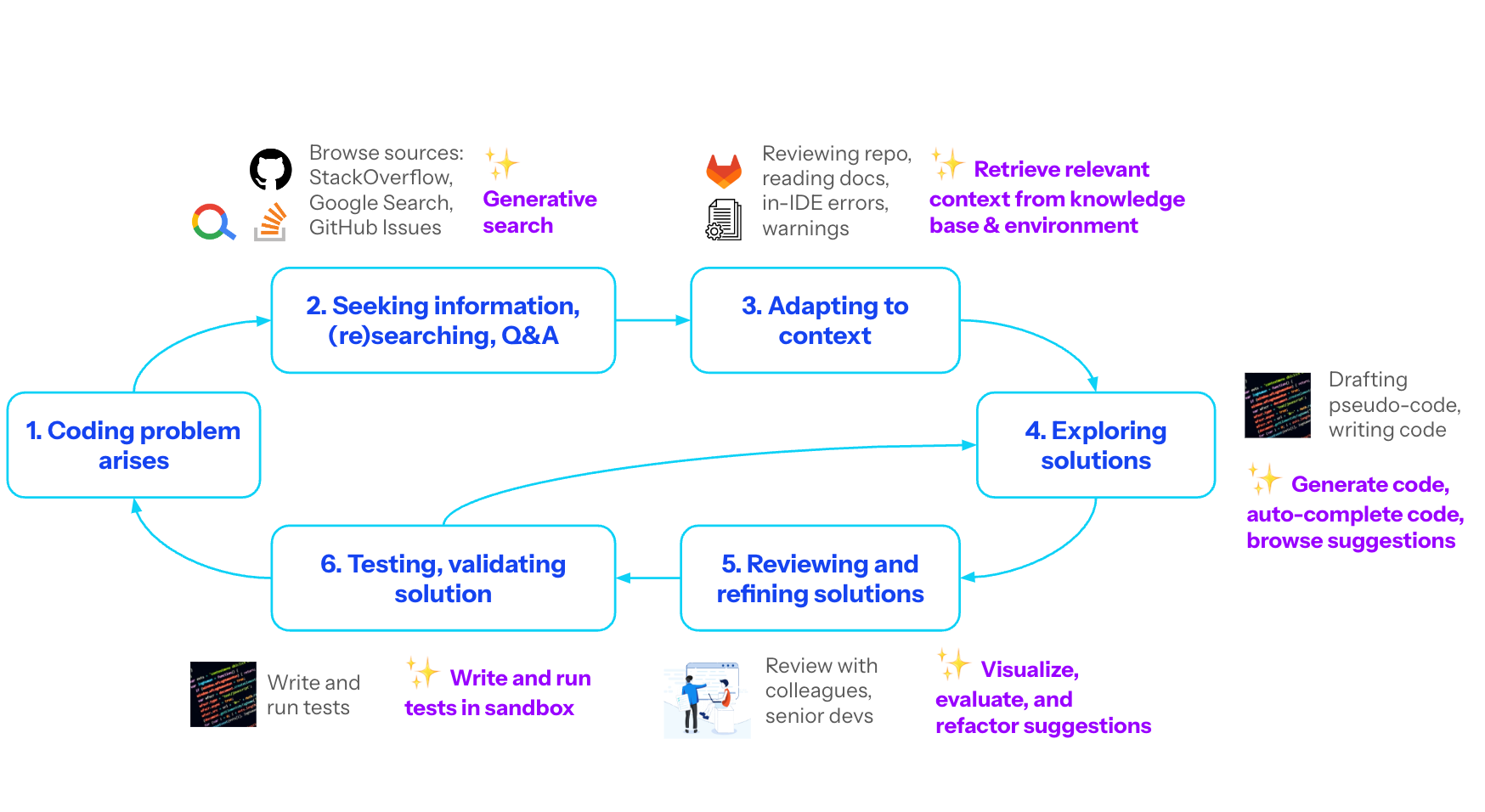
From this view, the next-generation AI coding assistant need not be a singular, human-like pair programmer, but instead a collection of tools that use emergent capabilities in AI and related technologies to enhance the coding experience. Each tool comes with its own sets of assumptions, capabilities, and limitations that should be clearly communicated to the users.
The biggest AI coding assistants, most notably GitHub Copilot, are following this model, positioning their products as bundles of features and capabilities, tailored in design to help developers at different stages of coding, with the first-generation code autocomplete assistant remaining the most popular and widely adopted offering, due to the straight-forward interaction model and clear value proposition.
Currently, the predefined commands and workflows are commonly triggered through special operators in the chat window or menu option selection. However, with improvements of intention slotting, I think we can achieve a more seamless experience, where AI coding assistants suggest predefined flows based on users’ natural language utterances.
Further readings:
- What is it like to program with AI?
- Designing for trust in AI coding tools
- Problems, causes, solutions of AI pair programming
2. In-IDE AI
Even from the early days of AI coding assistants, it was clear that programmers preferred to interact with AI where they spend the most time, in text editors and integrated development environments (IDEs). In-IDE AI allows developers to leverage the capabilities of AI without unnecessary context-switching.
We built our AI coding assistants as third-party extensions and plugins for IDEs. Starting in mid-2022, our first project was building an AI writer for docstrings and comments in Visual Studio Code (VS Code), JetBrains IDE, and Eclipse. We quickly learned the challenges of working within the constrained set of exposed APIs from these IDEs to implement features that adhere to the guidelines of human-centered AI.
Wishing to follow the principle of designing for human control, we planned an interface where upon user request, the AI agent writes and stages docstrings in the editor as discrete blocks of suggestions, with clear annotations that they were AI-generated. These blocks must remain uncommitted to the source code until manual user acceptance, unless configured otherwise.
Take VS Code for example, the only way to review staged changes is with the refactor preview panel, a high-friction experience. It takes the developer away from their working editor and requires a few clicks to close and return to the original view.
In order to implement a “staging before commit” experience right in the working editor view, our team had to build a custom UI component that we called CommentBlock. It used string and uri primitives to display annotated blocks of AI suggestions, with triggers to insert or ignore (accept or reject) individual or multiple blocks into the source code. Inevitably, the display is not as slick as other native UI components offered by VS Code.
However, as coding assistants became more widely adopted, we also saw IDEs evolving to meet the demand for more sophisticated UI/UX engineered for AI features.
In late 2023, GitHub Copilot Chat introduced the inline chat interface which allows users to trigger a pop-up AI code chat window on a highlighted snippet in the active editor, without having to open the side panel. It was a novel and nifty interface; however, the native building blocks to replicate such an experience were not available to third-party developers.
Since VSCode is open source, we discovered that the inline chat implementation in the source code used 10 VSCode APIs still in the proposed state. Proposed APIs are available for third-party developers, with a big caveat. Microsoft places restrictions on publishing extensions with these unstable APIs on the Marketplace, with the sole exception of GitHub Copilot Chat. So if we tried to use similar proposed APIs to GitHub Copilot Chat, we wouldn’t be able to release that build of our extension on the Marketplace. As a workaround, our team had to use the stable createCommentController API instead to build a scrappy implementation.
IDE developers are reimagining what an AI-aware IDE would look like, resulting in exciting innovations. The founders and developers of the Zed text editor shared insightful ideas in the discussion Building a Text Editor in the Times of AI. For example, Zed offers an experimental UI where the editor animates the changes between the user’s original code and the AI refactored version in a dynamic spot-edit style.
On the backend side, the Zed team revealed that they are improving their Zed-native AI assistants by re-using code insights from the same technical components required in smart IDEs such as a programming language server and parsers. Traditionally, these components enabled IDE capabilities such as syntax highlighting, autocompletion, warnings, etc. In the AI coding assistant context, the language server and parsers help collect and filter relevant context across the repository, working sessions, and knowledge base to enhance AI-generated suggestions.
Similarly, since both VS Code and GitHub Copilot are owned by Microsoft, the internal collaboration allows the AI coding assistant to access data and code insights from the text editor such as code workspace directory, recent files, user actions, etc.
However, as these capabilities remain inaccessible to third-party developers, we must independently implement similar capabilities in our applications.
Further readings:
- AI tools in project IDX
- A new generation of intelligent IDEs
- Embedding based search in JetBrains IDEs
IDEs are evolving with the AI-assisted developers in mind. As the community figures out preferred modes of interactions with AI while programming, we should expect to see a wave of new AI-aware interfaces, tools, and capabilities in IDEs.
3. Technical implementation
AI for software engineering is a fast-evolving field with new AI models, frameworks, applications libraries, and ideas emerging frequently. To keep up with this change, the technical implementation of AI coding assistants should remain flexible and agile, avoiding dependencies on any particular components.
That means the technical implementation of AI applications should focus on building persistent abstraction layers to communicate with each other, maintaining different versions with backward compatibility of APIs that allow flexible switching among different versions and configurations.
While building our own AI coding assistant, we developed several abstraction layers:
- Uniform LLMs layer: providing the same stateless request and response structure for LLMs across different providers (Microsoft Azure, Google Cloud, self-hosted HuggingFace TGI server for open source models)
- Uniform AI backend layer (Python): providing the same stateless request and response structure for every AI process (LangChain prompts and tools)
- Uniform representation of user messages in chat window as rich, structured content in a lexical editor
- Uniform chat socket APIs and HTTP APIs (NodeJS)
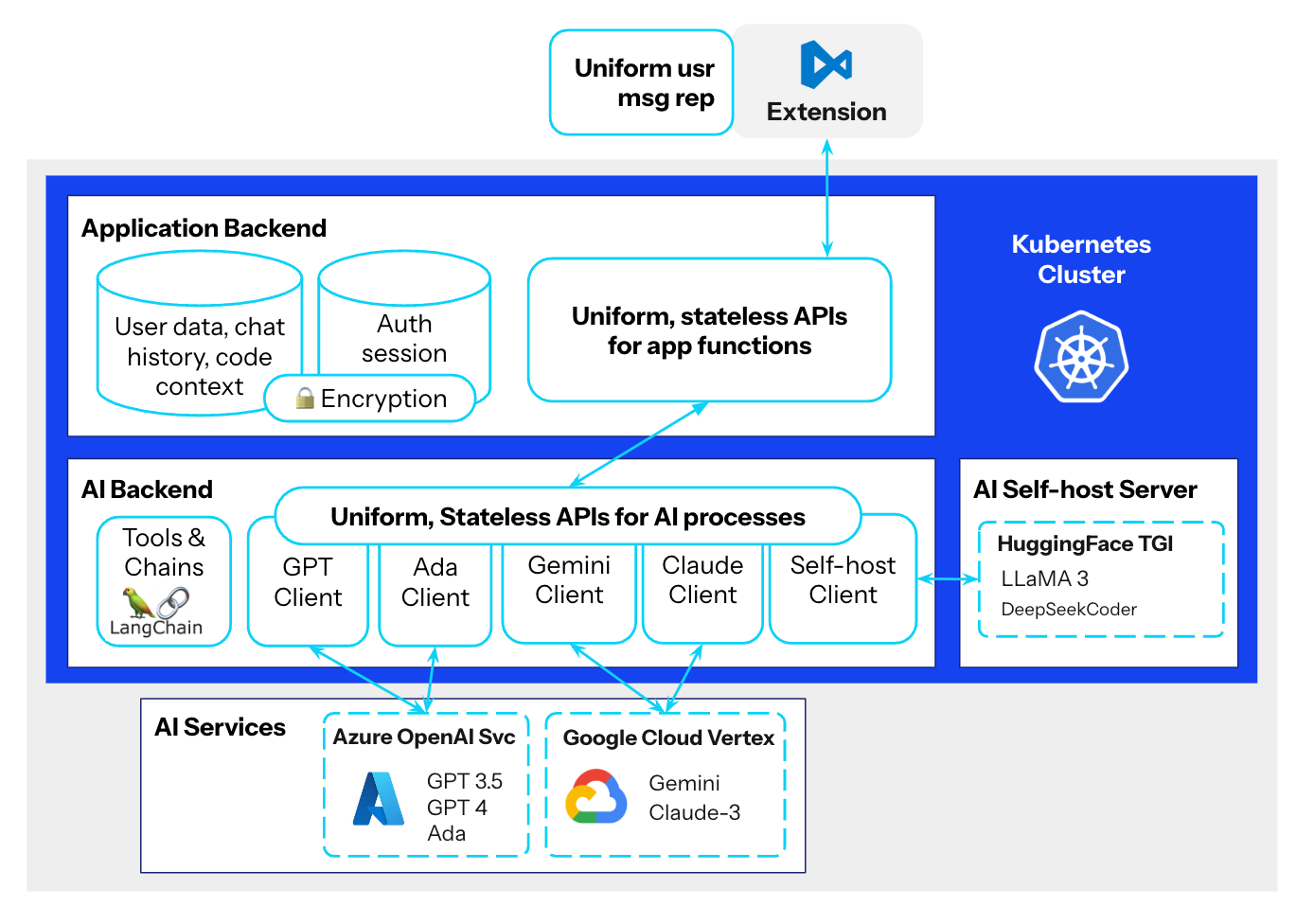
The abstraction layers allow our team to modify the underlying implementation of each component without cascading effects to other components. Separation of concerns enables team members to independently experiment with new technologies and incorporate them into the application.
For example, we were able to smoothly swap the self-hosted AI server framework from Nvidia Triton Server to HuggingFace TGI to improve inference speed and reliability without any modification needed for other layers. To achieve uniformity, we built a proxy to map parameters from different providers such as Microsoft Azure and Google Cloud, alongside with our own self-hosted AI server, to a uniform structure. As new models came out, it typically took us only a couple of business days to ship them to production since no refactoring at other layers was required.
Sourcegraph Cody takes the LLM abstraction to the next level by offering connectors to LLMs being served locally, while providing the same capabilities and features in their frontend and backend applications.
Since the AI backend layer (Python) and the LLMs inference services are stateless, we focus our engineering effort for sessions and state management in the application backend layer (NodeJS). Frequently accessed session data are stored in a Redis database and persistent user data such as request history, user-uploaded code files, logs, etc. are stored in a Mongo database. The loosely coupled, stateless design enables us to naturally leverage the scalable container-based architectures for application logic.
Similar to the spirit of making publicly available foundational LLMs, an entire implementation of an AI coding assistant system is now open source. The team at OpenDevin shares their open source coding assistant on GitHub and recently published a white paper that provides system design, implementation and evaluation details.
OpenDevin’s architecture embraces the same loosely-coupled containerized paradigm. They go the extra mile to maintain components for event streaming and agent skill list. These generic layers of abstraction add to the extensibility of the system, allowing rapid experimentation and expansion. By sharing these details with the larger community, OpenDevin helps lower the bar to entry for new teams on the scene, so they don’t have to start from scratch.
4. Studying impact
While we could generally agree that the goal of AI coding assistants is to improve developer’s productivity and happiness, we are still in the early stages of measuring and reporting where we are in achieving this goal.
Understanding of the impact of using AI is crucial for everyone,
- for end users: programmers need realistic expectations of personal gains from adopting AI in their workflows
- for organizations: managers and leaders need to decide whether investments in money and effort to operate and administer AI coding tools is worthwhile
- for AI tool developers: product teams need to know where and how to improve their AI coding assistants to better serve users
In an article published in May 2024, the research team at Microsoft and GitHub Copilot acknowledges ongoing challenges of studying AI impact on developers, despite the relavtively mainstream adoption of AI in coding. The main challenges come from the elusive nature of developer productivity and experience.
Firstly, there is the question of the “right” productivity metrics. Since programming is a complex activity, with many processes involved, it is hard to come up with a definitive set of metrics that comprehensively approximate AI impact across all the work developers do.
However, when we narrow down the scope to measuring productivity gains for an individual, well-defined activity, the metrics became more straightforward. For example, for the first tool we built – an AI docstring writer, the set of productivity metrics included:
- amount of code processed (kLOCs)
- suggestion acceptance rate
- doc coverage rate
- processing time
We measure these metrics with clear goal of increase the values of some metrics and decrease others through product improvements to boost developer productivity.
Generating docstrings and comments falls into the larger category of “generating natural language artifacts”, similar to writing README docs and pull request descriptions. While these artifacts are helpful to provide additional information for the source code, they don’t affect the quality of the software. They are not function-critical. Writing these artifacts are also often considered “toil” while making software, activities that developers usually want to delegate to automated, AI-assisted help.
As we move our focus to more function-critical activities, the productivity model starts to get complicated. Take generating unit tests for example. Running unit tests are crucial in development to make sure the code snippet will operate with the intended functionality under a wide range of input scenarios. Writing good unit tests involves writing natural language artifacts – a test plan with comprehensive test scenarios and corresponding test data, as well as writing code – implementations of the unit tests.
In this case, the quality of the natural language artifact is more consequential. If the AI-generated test plans are non-comprehensive or wrong, they will lead to missing and faulty test cases. Human supervision and revision is critical. The productivity model must consider significant effort for human review and the cost of overcoming human tendencies for AI overreliance. To be comprehensive, it should also consider potential cost of remediating issues resulted from AI mistakes.
In the code implementation step for unit testing, developers can get assistance from AI-suggested code generation. However, they must also spend significant effort to make sure the generated code is correct, especially in cases where generating unit tests for one function requires contextual dependencies from other classes and procedures. These variables do not only predicate on the product’s quality, but also personal and circumstantial factors that complicate analysis.
Secondly, there is the question of the right research methods and level of analysis. Published research in the field of human-computer interaction (HCI) often relies self-reported surveys and controlled-environment experiments.
Self-reported surveys help take a pulse of the user’s perception and sentiment of AI coding assistants. The results from self-reported surveys give insights into how the tools can improve the user experience. However, when talking about productivity, there is a gap between perceived versus actual productivity gains. Plus the framing of the questions and the participant’s individual biases might interplay to skew the survey results and subsequent interpretation. Besides, software development in a professional settings is often a team activity. There is little research on how individual productivity gains translate to collective teamwork success.
Controlled-environment experiments are typically setup where developers of specific skill levels (novice to expert) are given programming problems to solve in two settings – with and without AI help. Observations from these experiments can reveal patterns of human-AI interactions and how they differ within and across skill levels. However, these experiments are often conducted on a small scale with participants of specific backgrounds that limit the generability and scalability of the analysis.
Product teams building AI coding assistants have the unique opportunity to record, access, and analyze in-app metrics and telemetry to deduce insights about the tools’ impact. Of course, the collection and usage of user data must be transparently communicated, including the opportunity to opt-out.
One way that my previous team collect data for downstream analyses involves generating metadata tags of user and system chat messages. As a standard data privacy practice, the chat messages data are securely encrypted and only the conversation owner can uncover the content. To study user behaviors and hypothesize signals of impact, our system generates a series of metadata tags and made them available to a team of business analysts, including:
- user intent classification based on pre-defined taxonomy of various coding operations
- length of user prompts and length of appended code context in request
- length of system response and length of generated code in response
- generated code insertion rate into the working editor
- user rating (helpful / unhelpful) of messages
The data help us discover user usage patterns. The most popular intents for using the AI coding assistant among our users were code generation, bug fix, and information seeking. Users also had the tendencies to write short prompts without appending necessary contexts. Users were also more likely to rate the assistant’s response as “helpful” when they could directly insert generated snippets directly into their code.
To my knowledge, no AI coding assistant team has yet to publish an impact study based on in-app and telemetry metrics, although GitHub copilot mentioned they make inferences from user activities. In the future, I hope to see AI coding assistant teams share their methodologies, analyses, and insights from usage data, so the field can move forward in making the AI-assisted coding experience more productive, positive, and helpful for developers.
Conclusion
Working with AI for software engineering, I often felt a mix of awe, frustration, and cautious enthusiasm. The awe comes from expectation-defying emergent capabilities from foundational models and the innovative spirit of the community that bring cool ideas to life. The frustration comes from the failure scenarios where our features are not delivering results we hope for our users, and the endless list of challenges we face to build a good system. The cautious enthusiasm comes from the conviction that as a community, we can bring forth technological breakthroughs (or at the very least, incremental progress) to make AI more helpful for people. At the same time, we must talk to each other, share ideas about how to best go about solving these problems, since AI is not a benign pursuit, with major environmental, financial, technological, and social consequences if not done right. My hope is that I will look back at this blog post a year from now, feeling more awe than most about the progress that we will have collectively made.
comments powered by Disqus